Extraction prioritaire des doublons
L’utilitaire d’extraction des doublons vous permet d’identifier et de supprimer de manière sélective les enregistrements en double de votre base de données. Si vous fusionnez 2 fichiers ou plus, vous pouvez identifier les enregistrements qui sont communs entre eux. Ceci est utile pour supprimer les listes de suppression, également appelées Kill Files.
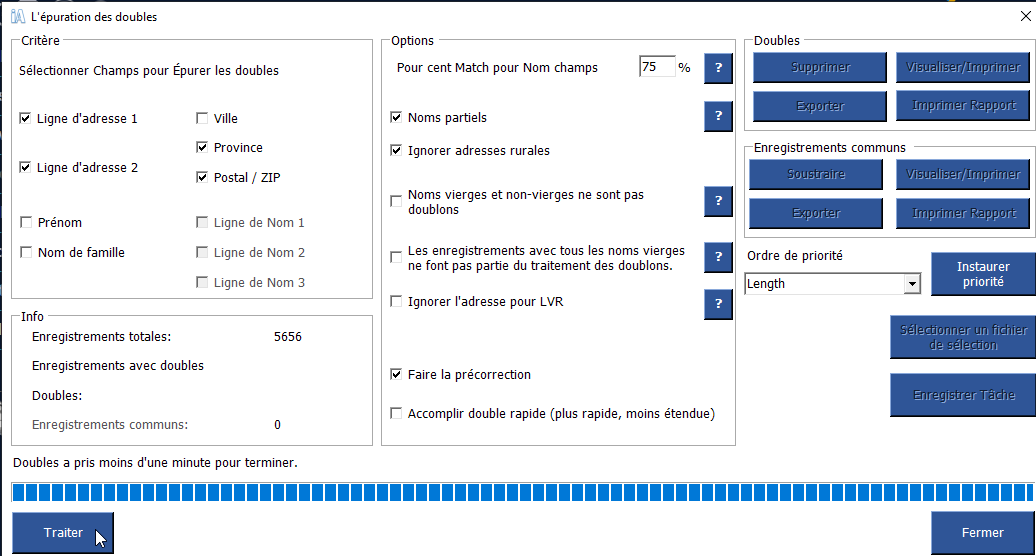
Dans le menu Gestion des adresses, sélectionnez « Extraction prioritaire des doublons ». Cliquez sur « Traiter » pour préformer l’extraction.
Par défaut, iAddress™ vérifie les enregistrements en double en fonction de l’adresse. Vous pouvez personnaliser votre duplication en choisissant une partie, la totalité ou aucune partie de l’adresse. « Ville » n’est pas sélectionné par défaut pour prendre en compte les autres noms de ville (par exemple Elk Falls, BC/Campbell River, BC ou North York, ON/Downsview, ON).
Vous pouvez également inclure d’autres champs pour identifier les doublons. Ceux-ci sont les suivants :
Prénom
Tous les enregistrements avec le même prénom seront identifiés. Le prénom ne sera disponible que si vous avez lié le champ du prénom lors de la création de votre travail.
Nom de famille
Les enregistrements avec le même nom de famille seront identifiés. Le nom de famille ne sera disponible que si vous avez lié le champ Nom de famille lors de la création de votre travail.
Ligne de nom (1, 2, 3)
Les enregistrements contenant les mêmes informations dans la ligne de nom appropriée seront marqués comme doublons.
Noms partiels
Les enregistrements sont identifiés si les noms sont similaires. Par exemple, Commercial Bank, Commercial Bank of Canada et Commercial seraient considérés comme des doublons tant que les adresses étaient les mêmes.
Ignorer les adresses rurales
By selecting this option, iAddress™ will not check rural addresses for duplicates. En sélectionnant cette option, iAddress™ ne vérifiera pas les adresses rurales pour les doublons.
Les lignes vides et non vides ne sont pas dupliquées
Si aucune donnée n’est contenue dans un champ, iAddress™ considérera qu’il s’agit d’une entrée unique et ne l’associera pas à des entrées non vides.
Les enregistrements avec tous les noms vides ne font pas partie du traitement des doublons
Tous les enregistrements dont tous les champs de nom sont vides sont exclus du processus lors de la vérification des doublons.
Les enregistrements avec tous les noms vides ne font pas partie du traitement des doublons
Tous les enregistrements dont tous les champs de nom sont vides sont exclus du processus lors de la vérification des doublons.
Pourcentage de correspondance
La valeur en pourcentage saisie dans cette zone permet à l’utilisateur de déterminer dans quelle mesure deux champs de nom doivent être similaires avant qu’ils ne soient identifiés comme doublons. Plus le pourcentage est élevé, plus les deux champs de nom doivent correspondre exactement. Pour trouver des correspondances exactes, le pourcentage doit être défini sur 100. La diminution de la valeur du pourcentage permettra des fautes d’orthographe.
Traitement des doublons
Pour vérifier les doublons dans votre base de données, sélectionnez le bouton « Traiter » et la barre de progression s’affichera au-dessus des boutons. Tous les enregistrements identifiés comme doublons sont signalés ; les enregistrements communs sont ceux identifiés dans votre liste de suppression (Kill File) qui apparaissent dans toutes les autres bases de données fusionnées dans votre travail.
Une fois le traitement terminé, vous pouvez choisir d’afficher vos enregistrements en double ou communs ou de les supprimer.
Rapport en double
Cliquez sur Imprimer le rapport pour produire une description détaillée de vos résultats d’extraction de doublons.
Pour afficher les doublons
La sélection de Afficher/Imprimer ouvre l’écran Afficher la base de données avec les doublons sélectionnés. À partir de cet écran, vous pouvez imprimer une liste d’adresses en double ou les supprimer de manière sélective. Vous pouvez également marquer ou retirer le drapeau des enregistrements en tant que doublons.
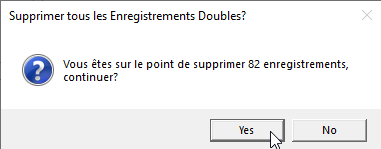
Suppression des doublons
Les doublons peuvent être automatiquement supprimés à l’aide de Supprimer les adresses en double.
Noter:
iAddress™ conservera automatiquement la première occurrence des adresses et supprimera tous les doublons supplémentaires trouvés.
Les informations sur les doublons peuvent être exportées à l’aide de l’option Champs de contrôle supplémentaires sur l’écran Exporter la base de données.
Pour exécuter votre travail
Après avoir sélectionné toutes vos options, cliquez sur « Traiter ».
Pour arrêter ce processus en cours d’exécution, cliquez sur « Annuler ».
Utiliser un fichier kill
Les fichiers Kill/Do Not Mail (listes de suppression) sont utilisés pour supprimer des adresses de la ou des bases de données principales. Si vous avez fusionné plus de 2 fichiers, vous devrez identifier le fichier kill. Cliquez sur le bouton « Select Kill File » et choisissez le fichier approprié. Après traitement, tous les enregistrements correspondant au fichier Kill seront marqués comme communs. Vous pouvez visualiser, imprimer et/ou exporter ces enregistrements. Lorsque vous êtes prêt à supprimer le fichier Kill et tous les enregistrements correspondants, cliquez sur soustraire.
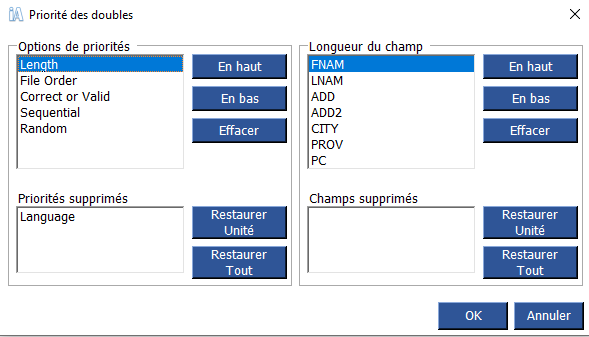
Définition des priorités pour les doublons
Vous pouvez décider lequel de vos critères d’identification en double est le plus important en définissant des priorités.
Dédoublonnage avant correction
Si vous traitez vos doublons avant de corriger votre fichier, vous devez choisir l’option Effectuer une précorrection. Cette option corrige et standardise vos enregistrements pour produire les meilleurs résultats.
Une fois vos critères et options sélectionnés, cliquez sur Définir la priorité. L’écran suivant va apparaitre. Vous pouvez déterminer quelles options sont les plus importantes en les déplaçant de haut en bas dans la liste. Si vous ne souhaitez pas utiliser une option particulière, vous pouvez les supprimer. Vous pouvez déplacer les éléments liés à chaque option dans la zone de droite. Vous pouvez également les supprimer, s’ils ne sont pas importants pour votre extraction des doublons.
Longueur
Cette option sélectionne le doublon avec le plus grand nombre de caractères. Par exemple, si cette option était sélectionnée pour le champ Prénom, JONATHON serait considéré comme un doublon de priorité supérieure à J ou JOHN. Lorsque vous supprimez vos doublons, JONATHON serait conservé tandis que J et JOHN seraient supprimés.
Commande de fichiers
Si vous avez fusionné deux fichiers ou plus, vous pouvez déterminer quel fichier est le plus important lors de la détermination des doublons. Par exemple, si le troisième fichier que vous fusionnez dans votre travail est votre liste de clients principale, vous pouvez la sélectionner comme priorité. Si des doublons sont trouvés dans votre dossier, les doublons trouvés dans votre liste de clients principale seront considérés comme une priorité plus élevée. Lorsque vous supprimez vos doublons, l’enregistrement de ce fichier sera conservé tandis que les autres seront supprimés.
Langue
Cette option priorisera les doublons par langue. Si l’anglais a été sélectionné comme priorité, les doublons français seront supprimés avant les doublons anglais.
Correct ou valide
Une partie du processus de normalisation standard implique une correction/validation. Vous pouvez utiliser ces informations pour définir des priorités avec vos doublons. En sélectionnant cette option, lorsque des doublons sont trouvés, les adresses valides recevront une priorité plus élevée. Lorsque vous supprimez vos doublons, un enregistrement valide sera conservé tandis que les autres seront supprimés.
Aléatoire
Si deux entrées ou plus sont des correspondances exactes, cette option en sélectionne une au hasard parmi les autres. Cette option est toujours le « dernier recours », c’est-à-dire que si d’autres priorités ont été sélectionnées et qu’il reste encore des doublons, la sélection aléatoire aura lieu.
Noter:
La liste déroulante à côté de Définir les priorités affiche les priorités que vous avez sélectionnées et l’ordre dans lequel elles seront appliquées à votre tâche.
Création d’enregistrements supérieure
Cette option vous permet de créer un enregistrement en utilisant des parties de deux ou plusieurs enregistrements en double. Une fois que vous avez traité vos doublons, vous pouvez accéder à cette fonction en cliquant sur le bouton « Afficher/Imprimer » et en sélectionnant « Fusionner » dans l’écran Afficher la base de données. Vous pouvez ensuite sélectionner des composants de chaque enregistrement en double pour créer une seule entrée dans votre base de données